شیائومی بهتازگی اولین مدل زبانی بزرگ (LLM) هوش مصنوعی استدلالی خود با نام MiMo را رونمایی کرده است. این مدل ۷ میلیارد پارامتری، اولین مدل منبعباز این شرکت در حوزه تواناییهای استدلالی است و قادر به انجام وظایف پیچیده در زمینههای ریاضی و تولید کد است. عملکرد MiMo با مدلهای بزرگتری همچون o1-mini شرکت OpenAI و Qwen-32B-Preview علیبابا قابل مقایسه است.
MiMo: اولین مدل هوش مصنوعی استدلالی متنباز شیائومی
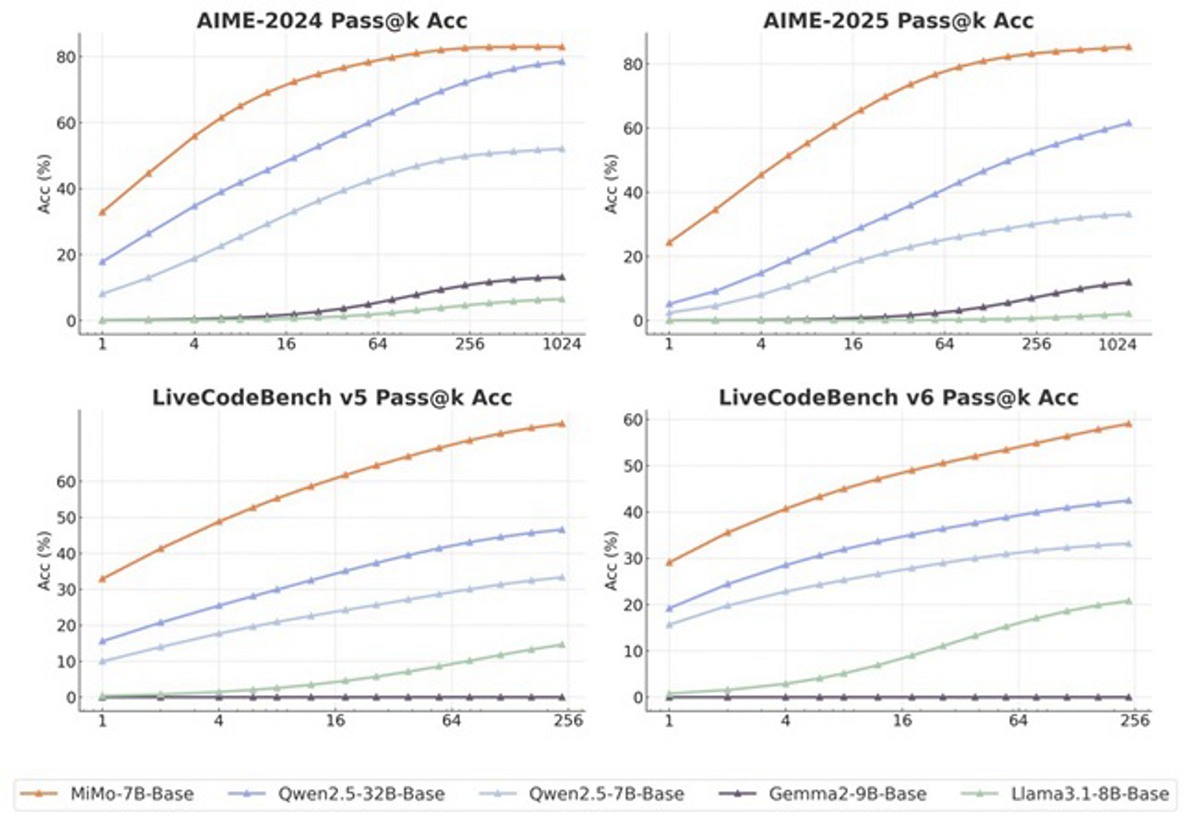
درحالی که اغلب مدلهای مؤثر در زمینه استدلال از معماریهای بسیار بزرگتری مانند مدلهای ۳۲ میلیارد پارامتری استفاده میکنند، ارائه چنین قابلیتهایی در قالب یک مدل کوچک امری چالشبرانگیز است. شیائومی معتقد است که توانمندی MiMo در حل مسائل منطقی، مدیون استراتژیهای بهینهسازیشده قبل و بعد از آموزش است. این موضوع میتواند آن را به گزینه مناسبی برای استفاده در دستگاههای هوشمند و محیطهای کسبوکار با منابع محدود تبدیل کند.

فرآیند آموزش اولیه
استدلال منطقی در MiMo بر اساس یک فرآیند آموزش بهینهسازیشده استوار است. تیم توسعه شیائومی خط پیشپردازش دادهها را ارتقا داده، ابزارهای استخراج متن را بهبود بخشیده و از فیلترهای چندلایهای برای افزایش تراکم الگوهای استدلالی استفاده کرد.
در این فرآیند، مجموعهدادهای شامل ۲۰۰ میلیارد توکن استدلالی جمعآوری شده و از یک استراتژی سهمرحلهای برای مخلوط دادهها استفاده شده است. این مدل روی ۲۵ تریلیون توکن در طی سه مرحله پیشرو آموزش داده شده است. همچنین شیائومی از «پیشبینی چند واژهای» (Multiple-Token Prediction) بهعنوان هدف آموزشی برای افزایش کارایی و کاهش زمان پردازش استفاده میکند.
اولین مدل هوش مصنوعی استدلالی متنباز شیائومی
فرآیند آموزش ثانویه
در مرحله پس از آموزش، تیم شیائومی از یادگیری تقویتی (Reinforcement Learning) با استفاده از ۱۳۰,۰۰۰ مسئله ریاضی و برنامهنویسی استفاده کرده است. این مسائل از نظر دقت و سطح دشواری با استفاده از سیستمهای قاعدهمحور اعتبارسنجی شدهاند.
برای غلبه بر مشکل «پاداش نادر» در وظایف پیچیده، تیم این شرکت از سیستم «پاداش مبتنیبر سختی تست» (Test Difficulty Driven Reward) استفاده کرده و همچنین از «نمونهگیری مجدد دادههای آسان» (Easy Data Re-Sampling) برای پایداری بیشتر یادگیری تقویتی در مسائل سادهتر بهره برد.
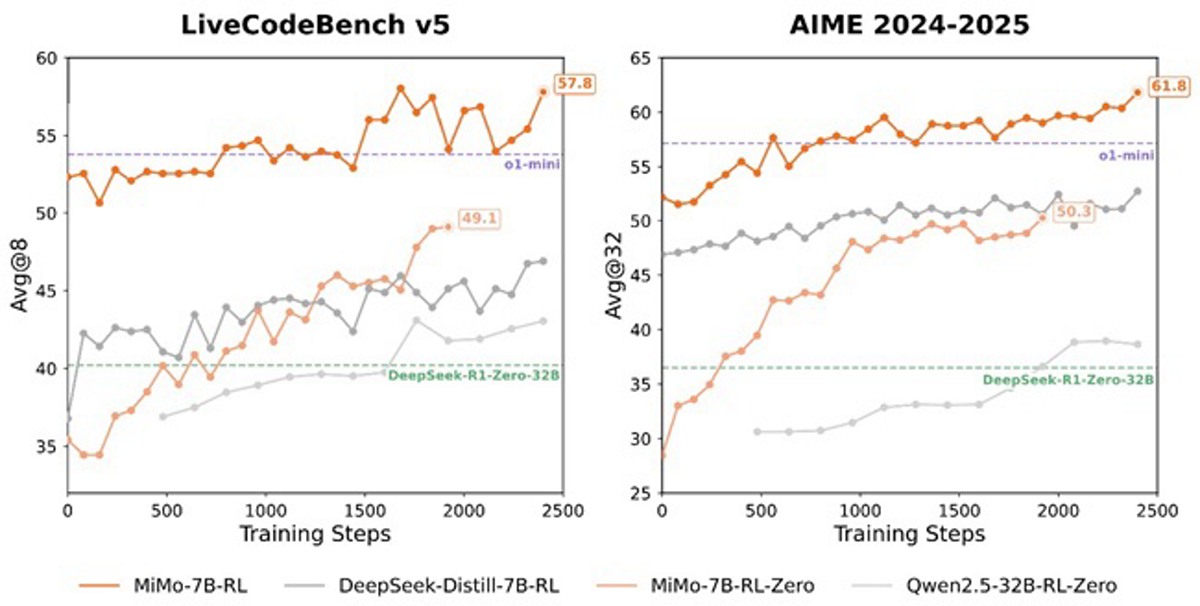
برای شتابدهی در مراحل آموزش و اعتبارسنجی، شیائومی موتور «اجرای بیوقفه» (Seamless Rollout Engine) را معرفی کرده است که زمان عدم فعالیت GPU را کاهش میدهد. این سیستم باعث شده سرعت آموزش ۲.۲۹ برابر و سرعت اعتبارسنجی ۱.۹۶ برابر افزایش یابد. علاوهبر این، این موتور از «پیشبینی چند واژهای» در vLLM پشتیبانی میکند و پایداری سیستم یادگیری تقویتی را بهبود میدهد.
انواع مدل MiMo
سری MiMo-7B شامل چهار نسخه مختلف است:
- MiMo-7B-Base: مدل پایه با ظرفیت بالای استدلال
- MiMo-7B-RL-Zero: مدل یادگیری تقویتشده از مدل پایه
- MiMo-7B-SFT: مدل ریز تنظیمشده تحت نظارت
- MiMo-7B-RL: مدل یادگیری تقویتشده از مدل SFT با عملکردی برجسته که با o1-mini شرکت OpenAI قابل مقایسه است
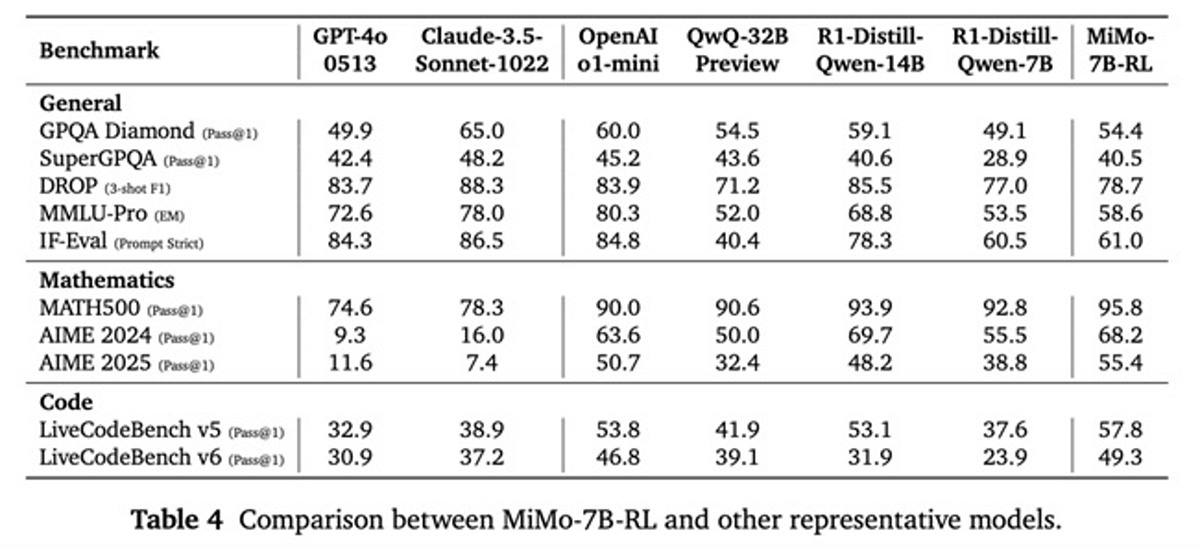
عملکرد در بنچمارکهای استاندارد
مدل MiMo-7B-RL در معیارهای مختلف عملکرد بسیار خوبی داشته است:
ریاضی:
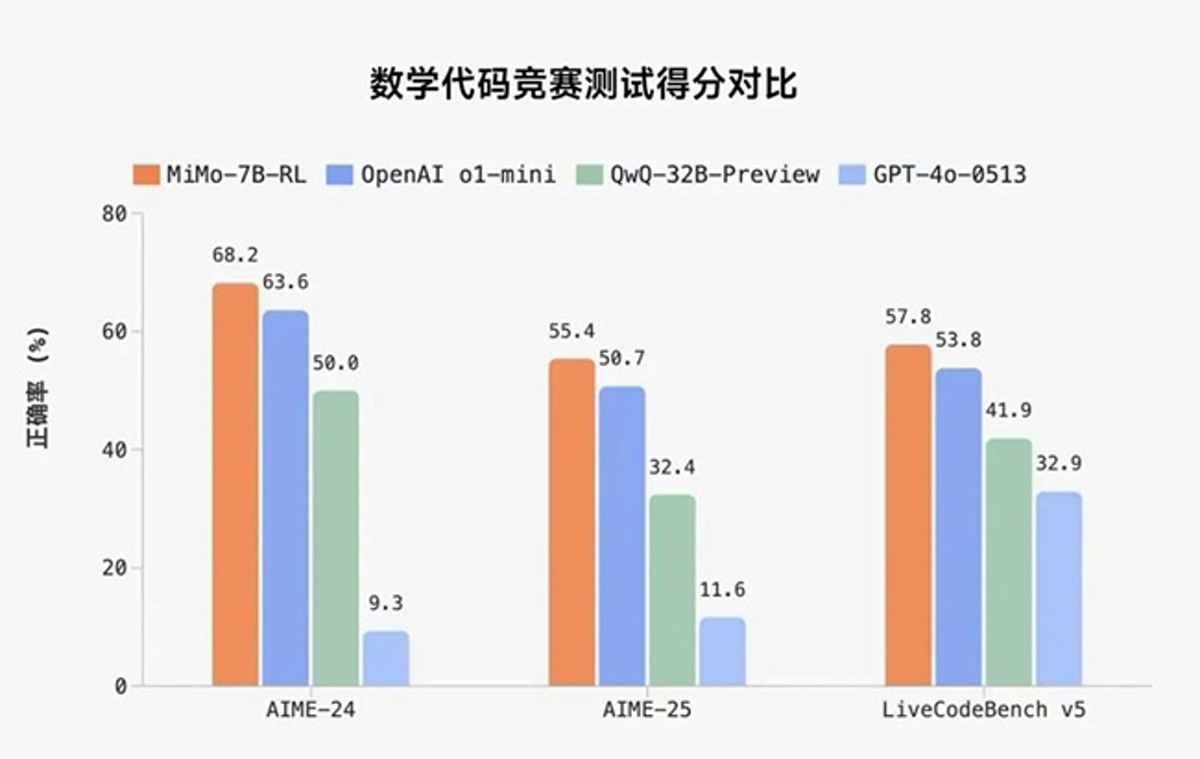
- MATH-500: دقت ۹۵.۸٪ (تک اجرا)
- AIME 2024: دقت ۶۸.۲٪ (میانگین ۳۲ اجرا)
- AIME 2025: دقت ۵۵.۴٪ (میانگین ۳۲ اجرا)
برنامهنویسی:
- LiveCodeBench v5: دقت ۵۷.۸٪ (میانگین ۸ اجرا)
- LiveCodeBench v6: دقت ۴۹.۳٪ (میانگین ۸ اجرا)
عمومی:
- GPQA Diamond: دقت ۵۴.۴٪ (میانگین ۸ اجرا)
- SuperGPQA: دقت ۴۰.۵٪ (تک اجرا)
- DROP (3-shot F1): دقت ۷۸.۷٪
- MMLU-Pro (Exact Match): دقت ۵۸.۶٪
- IF-Eval (Prompt Strict): دقت ۶۱.۰٪ (میانگین ۸ اجرا)
در دسترس بودن
کلیه مدلهای سری MiMo-7B بهصورت منبعباز منتشر شدهاند و در پلتفرم Hugging Face در دسترس عموم قرار دارند. گزارش فنی کامل و نقاط اجرایی مدل همراه با جزئیات آموزش و ارزیابی، در GitHub انتشار یافتهاند.
سخن پایانی
معرفی MiMo بهعنوان اولین مدل هوش مصنوعی منبعباز شیائومی، نویددهنده گسترش بیشتر تواناییهای هوش مصنوعی در مدلهای کوچکتر و قابل اجرا در دستگاههای با منابع محدود است. این دستاورد نشان از تعهد شیائومی در حوزه تحقیقاتی هوش مصنوعی دارد و میتواند نقطه شروعی برای همکاریهای بیشتر با جامعه توسعهدهندگان باشد.
نظر شما درباره اولین مدل هوش مصنوعی استدلالی منبعباز شیائومی چیست؟
بفرست برای دوستات
source