شرکت OpenAI با معرفی دو مدل استدلالی پیشرفته هوش مصنوعی خود با نامهای o3 و o3 mini، به اعلامیههای «Days of OpenAI 12» پایان داد.
مدل های o3 و o3 mini هوش مصنوعی OpenAI
o3 و o3 mini بهعنوان مدلهای پیشرفته استدلالی OpenAI معرفی شدهاند که اوایل امسال با مدل o1 منتشر شد. جالبتوجه است که OpenAI برای جلوگیری از درگیری یا سردرگمی احتمالی با شرکت مخابراتی بریتانیایی O2، از استفاده از عنوان «o2» صرفنظر کرده است.
مدل o3: تعیین استانداردهای جدید در استدلال و هوش
مدل o3 معیار جدیدی را برای استدلال و هوش ایجاد میکند و از مدل قبلی خود در حوزههای مختلف بهتر عمل میکند:
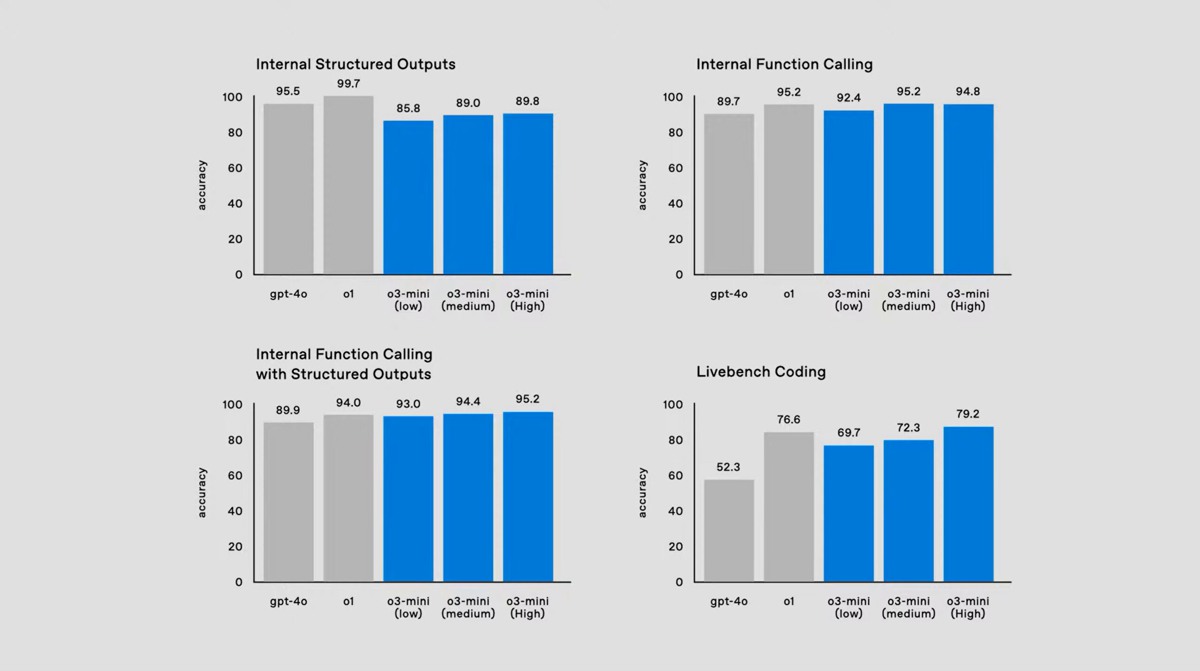
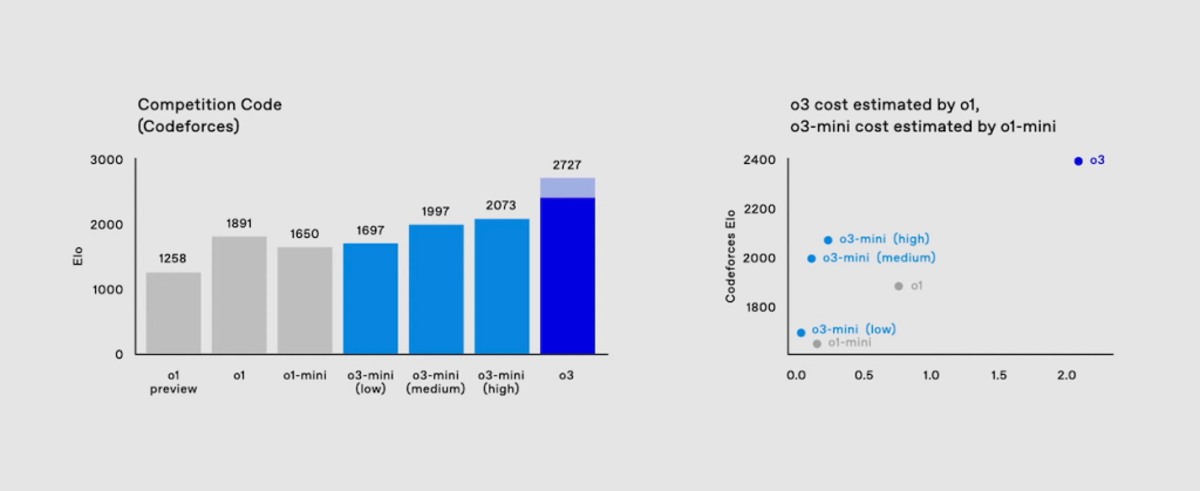
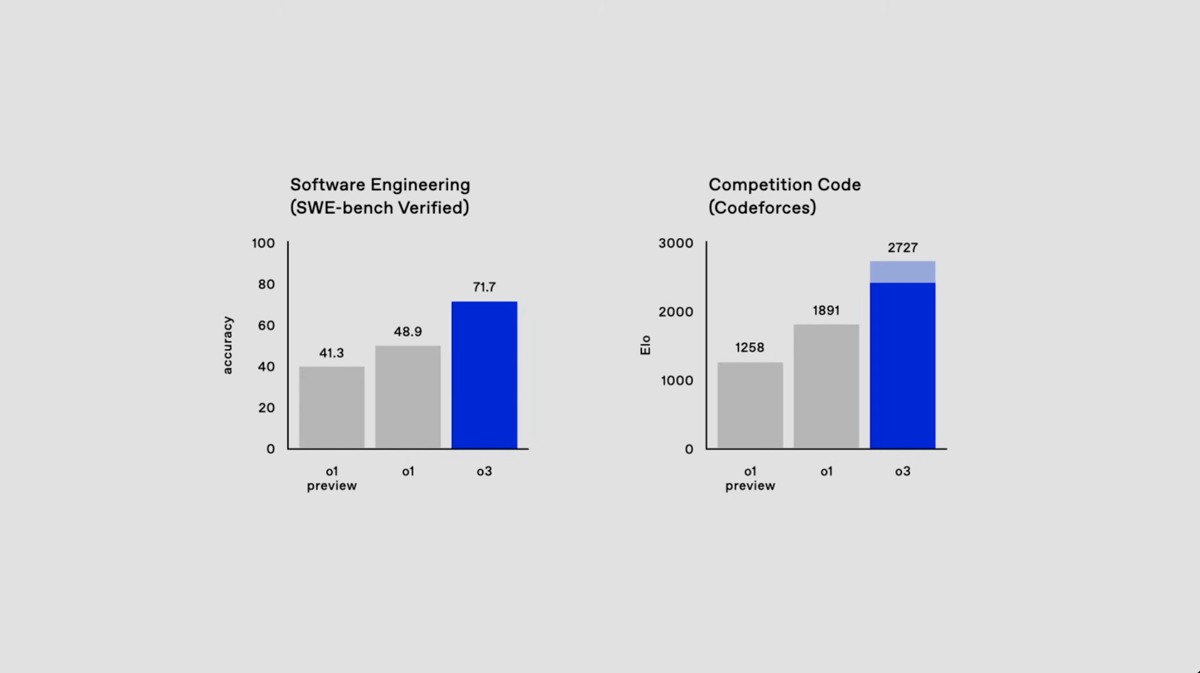
کدگذاری: به بهبود 22.8 درصدی در تستهای کدگذاری تأییدشده SWE-Bench در مقایسه با o1 دست یافت.
ریاضیات: تقریباً در آزمون AIME 2024 با نمره 96.7 درصد شرکت کرده و فقط یک سؤال را از دست داد.
علوم عمومی: کسب نمره 87.7 درصد در تست GPQA Diamond که مشکلات علمی در سطح متخصص را ارزیابی میکند، تضمین شده است.
معیار ARC-AGI: با کسب امتیاز 87.5 درصد در شرایط محاسباتی بالا، خط پنج ساله شکستناپذیری معیار ARC-AGI را شکست و از آستانه 85 درصدی انسان نیز گذشت.
معیار ARC-AGI با آزمایش توانایی یک مدل برای حل مسائل جدید بدون تکیهبر الگوهای حفظشده، هوش تعمیمیافته را ارزیابی میکند. با این دستاورد، OpenAI مدل o3 را بهعنوان یک گام مهم بهسمت هوش مصنوعی عمومی (AGI) توصیف میکند.
مدل های o3 و o3 mini هوش مصنوعی OpenAI
o3 Mini: یک جایگزین فشرده و مقرونبهصرفه
o3 mini یک نسخه خاص از o3 را ارائه میدهد که برای کارایی و مقرونبهصرفه بودن بهینه شده است:
برای کدنویسی و عملکرد سریعتر طراحی شده است.
دارای سه تنظیمات محاسباتی: کم، متوسط و زیاد.
در تنظیمات محاسباتی متوسط از مدل o1 بهتر عمل میکند و هزینهها و تأخیر را کاهش میدهد.
OpenAI همچنین Deliberative Alignment را نیز معرفی کرده است، یک الگوی آموزشی جدید با هدف بهبود ایمنی ازطریق ترکیب استدلال ساختاری همسو با استانداردهای ایمنی نوشتهشده توسط انسان. جنبههای کلیدی عبارتند از:
مدلها بهصراحت در استدلال زنجیرهای از فکر (CoT) که با خطمشیهای OpenAI هماهنگ است، درگیر میشوند.
نیاز به دادههای CoT با برچسب انسانی را حذف میکند و رعایت معیارهای ایمنی را افزایش میدهد.
پاسخهای حساس به زمینه و ایمنتر را در طول استنتاج در مقایسه با روشهای قبلی مانند RLHF و Constitutional AI فعال میکند.
آموزش و روششناسی
Deliberative Alignment هم از نظارت مبتنیبر فرآیند و هم نظارت مبتنیبر نتیجه استفاده میکند:
آموزش با وظایف کمکی شروع میشود، بهاستثنای دادههای ایمنی خاص.
مجموعه دادهای از دستورات مربوط به استانداردهای ایمنی برای تنظیم دقیق، توسعه داده شده است.
یادگیری تقویتی با استفاده از سیگنالهای پاداش مرتبط با رعایت ایمنی، مدل را اصلاح میکند.
نتایج:
مدل o3 در معیارهای ایمنی داخلی و خارجی بهتر از GPT-4o و سایر مدلهای پیشرفته عمل کرده است.
پیشرفتهای قابلتوجهی در اجتناب از خروجیهای نامناسب و درعینحال اجازه دادن به پاسخهای مناسب مشاهده شده است.
دسترسی زودهنگام و فرصتهای تحقیق
اولین نسخه از مدل o3 در اوایل سال 2025 منتشر خواهد شد. OpenAI از محققان ایمنی و امنیت دعوت کرده است تا برای دسترسی زودهنگام درخواست دهند.
OpenAI همچنان به اولویت تحقیقات ایمنی ادامه میدهد زیرا مدلهای استدلال بهطور فزایندهای پیچیده میشوند. این ابتکار با همکاریهای مداوم این شرکت با سازمانهایی مانند مؤسسههای ایمنی هوش مصنوعی ایالاتمتحده و بریتانیا همسو میشود و تضمین میکند که پیشرفتهای هوش مصنوعی، ایمن و سودمند باقی بماند.
بفرست برای دوستات
source